






Les entreprises accumulent des volumes de données que les méthodes classiques ne parviennent plus à exploiter efficacement.
Cette saturation ralentit l’analyse, limite la personnalisation des services et empêche d’extraire une valeur actionnable de ces informations. Le deep learning résout cette impasse en automatisant l’extraction de patterns complexes à partir de données non structurées.
Découvrez comment cette technologie fonctionne techniquement, où elle s’applique concrètement et quelles perspectives elle ouvre pour votre activité.
Comment fonctionne le deep learning et quelles sont ses architectures clés
Les réseaux de neurones artificiels et leurs couches
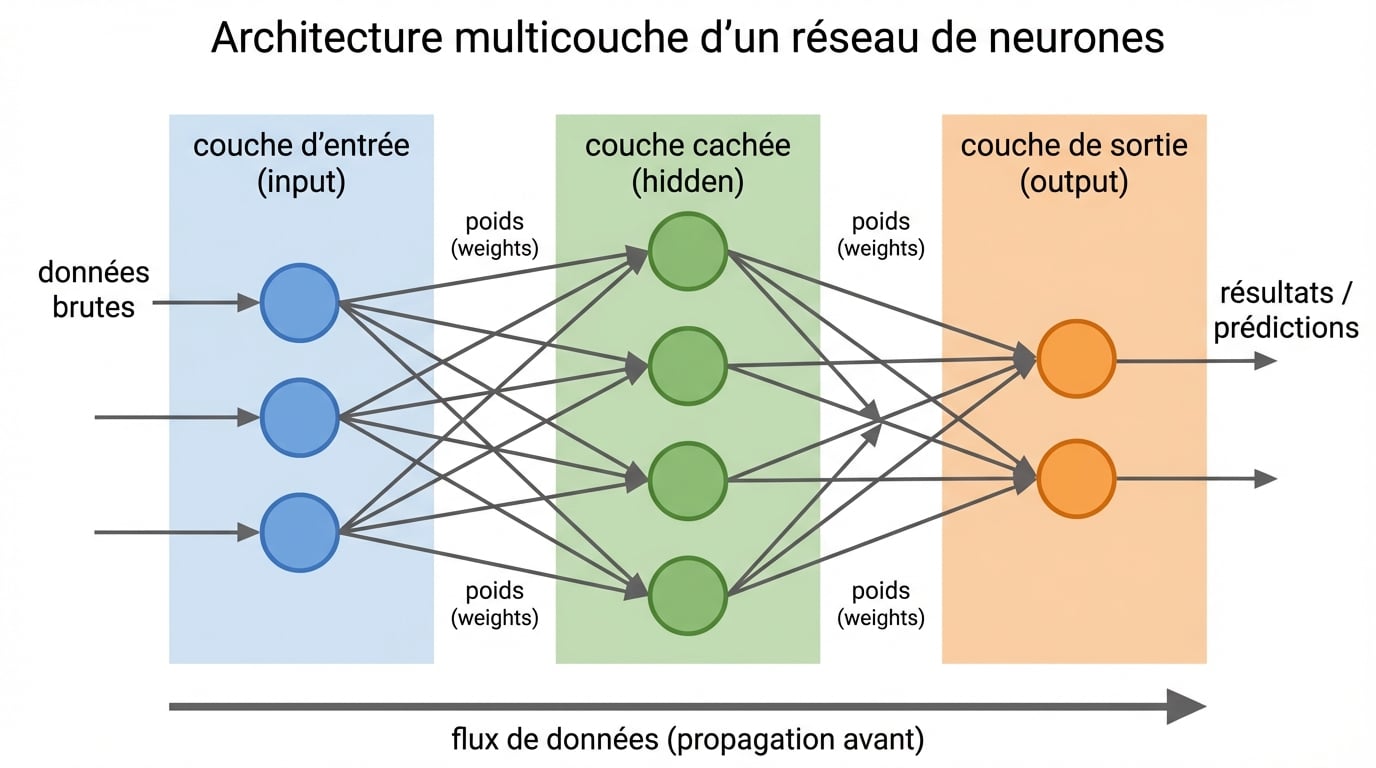
Un réseau de neurones artificiel se compose de trois types de couches qui traitent l’information de manière séquentielle. La couche d’entrée reçoit les données brutes, qu’il s’agisse de pixels d’une image, de mots d’un texte ou de valeurs numériques. Ces données transitent ensuite vers plusieurs couches cachées qui extraient progressivement des caractéristiques de plus en plus abstraites.
Chaque neurone calcule une somme pondérée des signaux reçus, puis applique une fonction d’activation qui introduit la non-linéarité nécessaire à la modélisation de relations complexes. Les fonctions ReLU, Sigmoid ou Tanh transforment cette somme en un signal transmis à la couche suivante. Cette architecture hiérarchique permet d’apprendre des représentations à plusieurs niveaux de complexité.
Les premières couches cachées détectent des motifs simples comme des contours ou des arêtes dans une image. Les couches intermédiaires reconnaissent des formes géométriques plus élaborées. Les dernières couches identifient des objets complets ou des concepts abstraits. La couche de sortie produit la prédiction finale, que ce soit une classification, une valeur numérique ou une séquence de texte.
Le processus d’apprentissage par rétropropagation
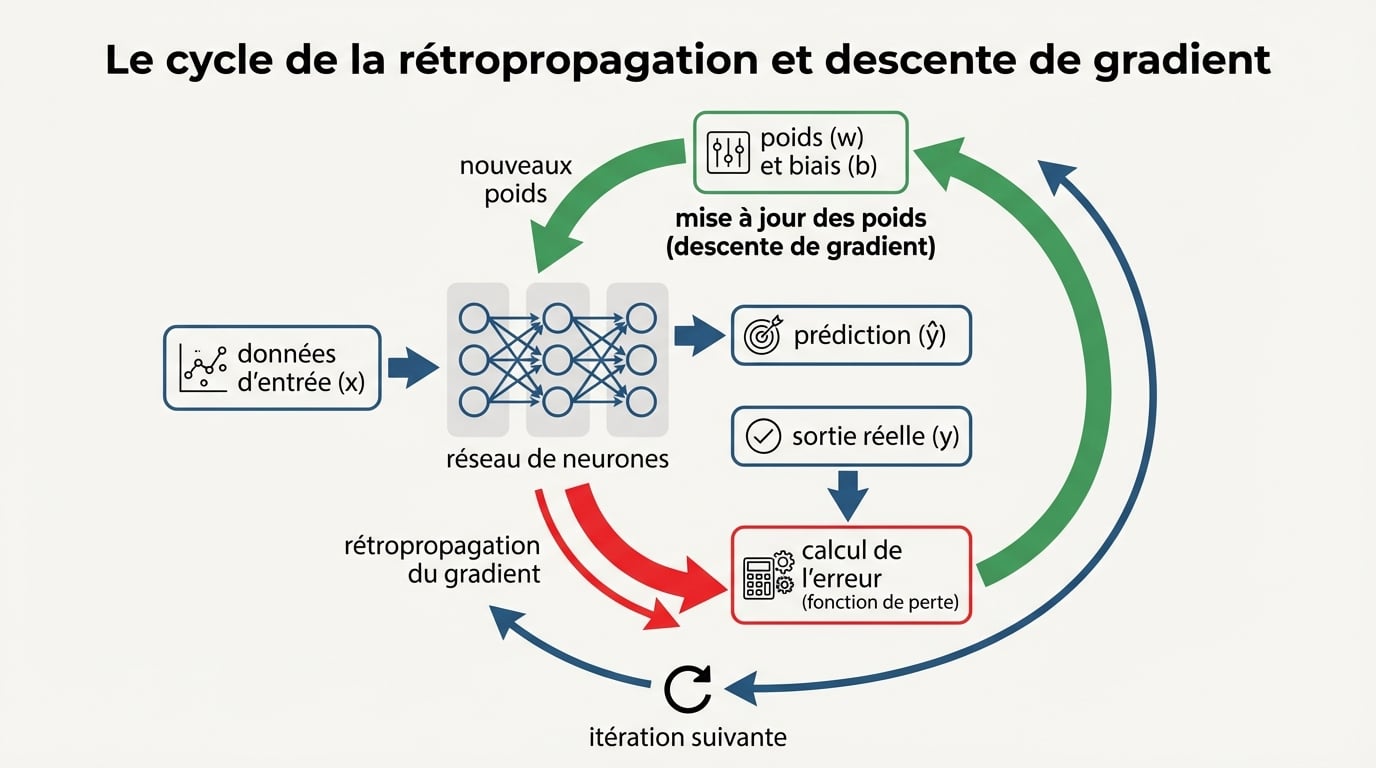
L’entraînement d’un réseau neuronal repose sur un cycle itératif qui ajuste progressivement les poids de chaque connexion. La propagation avant fait circuler les données à travers toutes les couches pour générer une prédiction. Une fonction de perte mesure ensuite l’écart entre cette prédiction et la valeur réelle attendue.
La rétropropagation propage cette erreur en sens inverse à travers le réseau. L’algorithme calcule la contribution de chaque poids à l’erreur totale grâce aux dérivées partielles. La descente de gradient modifie ensuite ces poids dans la direction qui minimise la perte. Ce processus se répète sur des milliers d’exemples regroupés en batches, sur plusieurs époques d’entraînement.
Cette méthode exige des volumes importants de données étiquetées et une puissance de calcul élevée, généralement fournie par des GPU. Plus le réseau contient de couches et de neurones, plus il peut modéliser des relations complexes, mais plus il nécessite de données et de temps pour converger vers une solution optimale.
Les principales architectures (CNN, RNN, Transformers)
Les réseaux de neurones convolutifs (CNN) dominent la vision par ordinateur grâce à leur capacité à détecter des motifs spatiaux. Ils appliquent des filtres qui balaient l’image pour identifier des caractéristiques locales, puis combinent ces informations à travers des couches de pooling qui réduisent la dimensionnalité. AlexNet a marqué un tournant en 2012 en remportant la compétition ImageNet avec une précision inédite.
Les réseaux récurrents (RNN) et leurs variantes LSTM traitent les données séquentielles en conservant une mémoire des informations précédentes. Cette architecture convient aux tâches impliquant du texte, de la parole ou des séries temporelles, où l’ordre des éléments influence le sens. Les LSTM résolvent le problème de disparition du gradient qui limitait les RNN classiques sur les longues séquences.
Les Transformers, introduits en 2017, ont révolutionné le traitement du langage naturel en s’appuyant sur un mécanisme d’attention. Ce système permet au modèle de pondérer l’importance relative de chaque élément d’une séquence, sans contrainte de proximité. BERT et GPT exploitent cette architecture pour générer du texte, traduire des langues ou répondre à des questions avec une fluidité proche du langage humain.
Les cas d’usage concrets du deep learning par secteur
Vision par ordinateur et reconnaissance d’images
La reconnaissance faciale sécurise l’accès aux appareils et aux espaces physiques en identifiant les individus avec une précision dépassant 99 % dans des conditions optimales. Les systèmes de vidéosurveillance analysent en temps réel les flux vidéo pour détecter des comportements suspects ou retrouver des personnes disparues. Cette technologie représente 35,23 % du marché du deep learning en 2025.
Les véhicules autonomes s’appuient sur des CNN pour identifier piétons, panneaux de signalisation et autres véhicules dans leur environnement. Ces modèles traitent simultanément les images de plusieurs caméras et capteurs pour prendre des décisions de navigation en millisecondes. La détection d’objets atteint désormais une fiabilité suffisante pour des déploiements commerciaux limités dans des zones géographiques contrôlées.
Les plateformes de réseaux sociaux utilisent le deep learning pour modérer automatiquement les contenus violents, haineux ou illégaux. Ces systèmes analysent des millions d’images et de vidéos par jour, réduisant le besoin de modération humaine tout en accélérant les temps de réponse. Les applications médicales exploitent cette même technologie pour analyser des radiographies ou des IRM avec une précision comparable à celle des spécialistes.
Traitement du langage naturel et chatbots
Les assistants virtuels comme Alexa ou Siri comprennent les requêtes vocales et y répondent en langage naturel grâce à des modèles de deep learning. Ces systèmes convertissent d’abord la parole en texte, analysent l’intention de l’utilisateur, puis génèrent une réponse appropriée avant de la synthétiser en audio. Cette chaîne de traitement s’exécute en quelques secondes pour offrir une interaction fluide.
Les robots conversationnels automatisent le support client en traitant les demandes récurrentes sans intervention humaine. Ils réduisent les coûts opérationnels tout en garantissant une disponibilité 24h/24. Les entreprises les déploient sur leurs sites web, applications mobiles et messageries pour qualifier les prospects, traiter les réclamations ou guider les utilisateurs dans leurs parcours d’achat.
Les outils de traduction comme DeepL ou Google Translate exploitent les Transformers pour produire des traductions contextuelles qui respectent les nuances linguistiques. Ces modèles apprennent les correspondances entre langues à partir de millions de paires de phrases parallèles. La génération de texte s’applique également à la rédaction automatisée de rapports, de résumés ou de recommandations personnalisées.
Applications médicales et diagnostic de santé
Quel modèle de Deep Learning pour votre projet ?
Architecture recommandée :
Les algorithmes de deep learning détectent les mélanomes sur des images dermatologiques avec une sensibilité supérieure à celle de dermatologues expérimentés. Ces modèles identifient des patterns visuels subtils qui échappent à l’œil humain, permettant un dépistage précoce qui améliore significativement le pronostic. Le secteur de la santé affiche un taux de croissance annuel de 36,75 %, porté par ces avancées diagnostiques.
AlphaFold a révolutionné la biologie structurale en 2021 en prédisant la forme tridimensionnelle des protéines à partir de leur séquence d’acides aminés. Cette capacité accélère la recherche pharmaceutique en permettant d’identifier des cibles thérapeutiques et de concevoir des médicaments de manière plus efficace. Des milliers de structures protéiques ont été élucidées en quelques mois, contre des décennies par les méthodes expérimentales traditionnelles.
L’analyse d’imagerie médicale bénéficie du deep learning pour détecter des tumeurs, des fractures ou des anomalies vasculaires. Les radiologues utilisent ces outils comme une seconde opinion qui réduit les faux négatifs et accélère les diagnostics. Les systèmes de prédiction de risques exploitent les dossiers médicaux électroniques pour anticiper les complications, les réadmissions hospitalières ou l’évolution de maladies chroniques.
Automobile, finance et autres secteurs en transformation
Le secteur automobile intègre le deep learning au-delà de la conduite autonome, notamment pour optimiser la consommation énergétique, prédire les pannes et personnaliser l’expérience de conduite. Les constructeurs analysent les données des capteurs embarqués pour ajuster en temps réel les paramètres moteur, freinage et suspension. Cette analyse améliore la sécurité tout en prolongeant la durée de vie des composants.
Le secteur bancaire et des assurances (BFSI) représente 24,12 % du marché du deep learning. Les établissements financiers détectent les fraudes par carte bancaire en analysant les patterns de transactions et en identifiant les anomalies en temps réel. Les algorithmes de trading haute fréquence exploitent les réseaux de neurones pour anticiper les mouvements de marché et exécuter des ordres en microsecondes.
| Secteur | Application principale |
|---|---|
| Retail | Recommandations personnalisées |
| Énergie | Prédiction de consommation |
| Industrie | Maintenance prédictive |
| Sécurité | Détection d’intrusions |
| Agriculture | Analyse de cultures par drone |
Les jeux vidéo utilisent le deep learning pour créer des adversaires adaptatifs qui apprennent du comportement des joueurs. AlphaGo a démontré cette capacité en battant les champions mondiaux de Go entre 2015 et 2016, un jeu considéré comme trop complexe pour les approches algorithmiques classiques. Cette technologie s’étend désormais à la génération procédurale de contenus et à l’amélioration graphique en temps réel.
Avantages, limites et perspectives d’avenir du deep learning
Les forces du deep learning face aux données massives
La capacité d’apprentissage automatique des caractéristiques distingue le deep learning des approches classiques qui nécessitent une ingénierie manuelle des features. Les réseaux de neurones découvrent par eux-mêmes les représentations pertinentes à partir des données brutes, réduisant le travail préparatoire et accélérant le développement de modèles. Cette automatisation permet de traiter des types de données variés sans expertise métier approfondie.
La scalabilité horizontale des architectures modernes autorise leur déploiement sur des clusters de GPU ou de TPU pour traiter des pétaoctets de données. Plus le volume d’entraînement augmente, plus la précision des modèles s’améliore, contrairement aux méthodes traditionnelles qui plafonnent rapidement. Les modèles pré-entraînés peuvent être affinés sur des tâches spécifiques avec des jeux de données réduits, démocratisant l’accès à cette technologie.
Les avantages mesurables incluent :
- Précision supérieure aux humains sur des tâches spécialisées comme la classification d’images médicales
- Traitement en temps réel de flux de données massifs pour des décisions instantanées
- Généralisation cross-domaine grâce au transfer learning qui réutilise les connaissances apprises
- Adaptation continue par réentraînement incrémental sur de nouvelles données
Les défis techniques et éthiques à surmonter
Les modèles de deep learning fonctionnent comme des boîtes noires dont les décisions restent difficiles à interpréter. Cette opacité pose problème dans les domaines réglementés comme la santé ou la finance, où la traçabilité des décisions détermine la conformité légale. Les techniques d’explicabilité comme LIME ou SHAP tentent de lever ce voile, mais n’offrent que des approximations partielles du raisonnement interne.
L’intensité computationnelle génère des coûts énergétiques significatifs et une empreinte carbone élevée. L’entraînement d’un grand modèle de langage peut émettre autant de CO2 que cinq voitures sur leur durée de vie complète. La démocratisation du deep learning exige des architectures plus efficientes et des stratégies d’optimisation qui réduisent ces besoins sans sacrifier les performances.
Les risques éthiques comprennent :
- Biais algorithmiques qui reproduisent ou amplifient les discriminations présentes dans les données d’entraînement
- Deepfakes qui manipulent images et vidéos pour diffuser de la désinformation
- Surveillance de masse facilitée par la reconnaissance faciale généralisée
- Concentration du pouvoir technologique dans les mains de quelques acteurs disposant des ressources nécessaires
L’évolution du marché et les tendances futures
Le marché mondial du deep learning atteindra 296,23 milliards USD en 2031, avec un taux de croissance annuel composé de 35,48 %. L’Amérique du Nord conserve 32,12 % des parts en 2025, tandis que l’Asie-Pacifique affiche la croissance la plus rapide à 35,92 %. Les secteurs de l’automobile autonome et de la robotique progressent à 37,2 % annuellement, stimulés par les investissements massifs des constructeurs.
| Région | Part de marché 2025 |
|---|---|
| Amérique du Nord | 32,12 % |
| Europe | 26,85 % |
| Asie-Pacifique | 28,43 % |
| Reste du monde | 12,60 % |
Les Transformers continueront leur expansion au-delà du langage naturel vers la vision, l’audio et les données multimodales. Les modèles foundation entraînés sur des corpus gigantesques serviront de base à des applications spécialisées via le fine-tuning. L’apprentissage fédéré permettra d’entraîner des modèles sur des données distribuées sans les centraliser, préservant ainsi la confidentialité.
Geoffrey Hinton a reçu le prix Nobel de physique en 2024 pour ses contributions fondatrices au deep learning, reconnaissance institutionnelle qui valide la maturité scientifique du domaine. Les prochaines avancées porteront sur l’efficience énergétique, l’explicabilité et la robustesse face aux attaques adversariales qui manipulent les entrées pour tromper les modèles.



