






Machine learning, principes et applications pratiques
Le machine learning est une branche de l’intelligence artificielle qui apprend des modèles statistiques à partir de données plutôt qu’à partir de règles codées en dur. Vous y trouvez trois familles, supervisée, non supervisée et par renforcement, qui couvrent la classification, la prédiction, la segmentation et l’optimisation.
Le vrai travail se joue en amont, dans la qualité des données et le pipeline MLOps, puis en aval dans la surveillance du modèle en production. Les cas d’usage vont de la maintenance prédictive à la détection de fraude, en passant par la recommandation et la vision industrielle.
Machine learning, définition et place parmi l’IA et le deep learning
Le machine learning, ou apprentissage automatique, désigne un ensemble de méthodes statistiques qui infèrent des motifs depuis des données. Vous ne codez plus la règle, vous fournissez des exemples et un algorithme ajuste ses paramètres. C’est une sous-discipline de l’intelligence artificielle, plus large, qui englobe aussi la logique symbolique et les systèmes experts.
Le deep learning est un sous-ensemble du machine learning basé sur des réseaux de neurones profonds à plusieurs couches. Il domine les tâches de perception, vision et langage, mais consomme beaucoup plus de données et de calcul que des modèles classiques. Des arbres comme XGBoost restent souvent plus performants sur des données tabulaires d’entreprise.
Pour comprendre où le ML s’inscrit dans l’écosystème actuel des modèles génératifs, voyez notre dossier sur l’IA générative et ses principes. La référence académique historique reste les cours de Stanford et le manuel de scikit-learn, qui formalisent très bien ces distinctions.
Les trois familles d’apprentissage qui structurent le machine learning
Quel type de machine learning pour votre problème ?
Six questions rapides, une recommandation immédiate avec algorithme type.
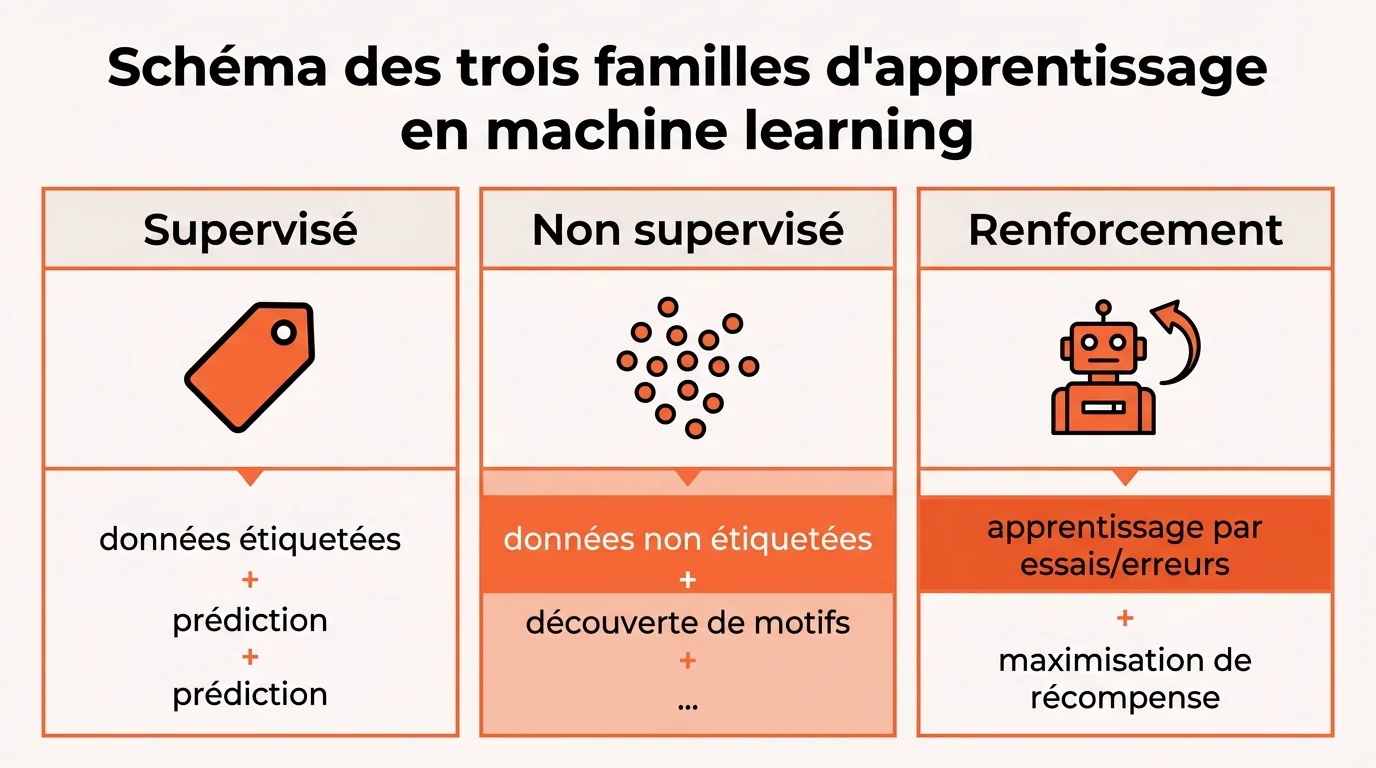
Trois paradigmes couvrent l’essentiel des usages industriels. Le choix dépend de vos données, étiquetées ou non, et de la nature du problème, prédiction ou décision séquentielle. Voici la comparaison synthétique que vous pouvez afficher côté équipe data.
| Famille | Données | Sortie attendue | Exemples d’algorithmes |
| Supervisé | Étiquetées | Classe ou valeur | Régression linéaire, SVM, XGBoost |
| Non supervisé | Non étiquetées | Groupes ou structure | K-means, DBSCAN, PCA |
| Renforcement | Interactions | Politique d’action | Q-learning, PPO, A3C |
Apprentissage supervisé et régression
Vous disposez de paires entrée-sortie connues, par exemple des e-mails étiquetés spam ou non. L’algorithme apprend une fonction qui généralise sur de nouvelles entrées. C’est le paradigme le plus utilisé en entreprise car il s’évalue simplement avec une métrique claire.
La régression prédit une valeur continue comme un prix ou une consommation. La classification renvoie une classe discrète comme un risque de churn. Les algorithmes de référence incluent les forêts aléatoires, les gradient boostings et les réseaux de neurones simples.
Apprentissage non supervisé et clustering
Les données n’ont pas d’étiquettes et vous cherchez une structure cachée. Le clustering regroupe des observations similaires, la réduction de dimension compresse l’information sans perdre l’essentiel. Utile pour la segmentation client, la détection d’anomalies et l’exploration d’un jeu de données.
Les méthodes emblématiques sont K-means, le clustering hiérarchique, DBSCAN pour les formes non convexes et PCA pour projeter en 2D ou 3D. Vous validez qualitativement, souvent avec un expert métier, puisqu’il n’y a pas de vérité terrain.
Apprentissage par renforcement
Un agent interagit avec un environnement et maximise une récompense cumulée. Ce cadre convient aux décisions séquentielles comme le trading algorithmique, le pilotage robotique ou l’optimisation de réseaux logistiques. L’entrainement est coûteux et demande un simulateur fiable.
Les travaux de DeepMind sur AlphaGo et AlphaFold illustrent la puissance du renforcement profond. Les papiers de référence publiés sur arXiv cs.LG documentent les avancées récentes sur PPO et les méthodes actor-critic.
Du jeu de données au modèle déployé, le pipeline en pratique
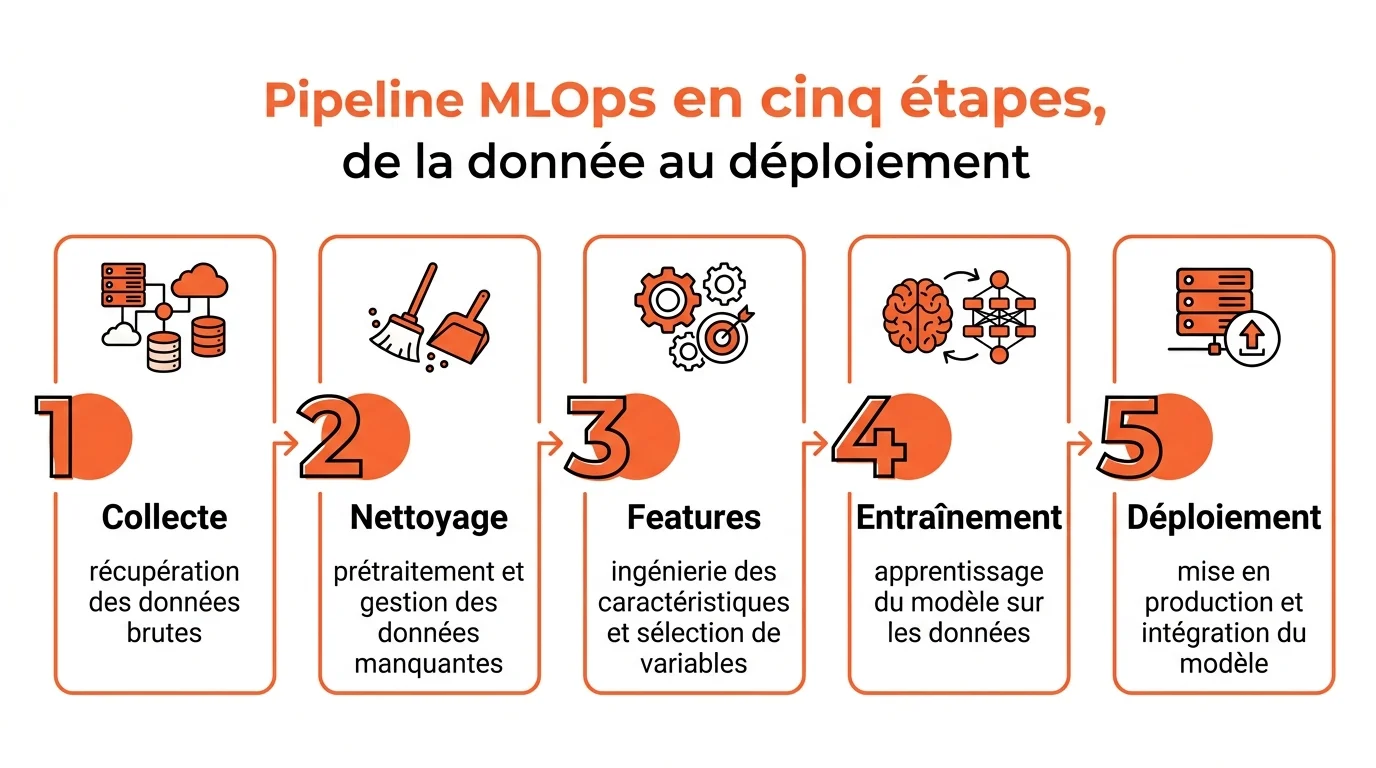
Un projet de machine learning réussi se joue autant dans l’infrastructure que dans le modèle. Selon AWS et Google Cloud, jusqu’à 80 pour cent du temps des équipes passe dans la préparation des données plutôt que dans la modélisation. Voici les étapes clés à verrouiller.
- Collecte et labellisation des données brutes depuis vos sources métiers
- Nettoyage, imputation des valeurs manquantes et détection d’outliers
- Feature engineering et stockage dans un feature store partagé
- Entraînement avec cross-validation et suivi des expériences
- Déploiement conteneurisé avec CI/CD et surveillance du drift
La discipline qui orchestre ces étapes s’appelle MLOps. Elle emprunte au DevOps la notion de pipeline versionné, et ajoute le registre de modèles, le suivi des features et la détection de dérive en production. Pour aller plus loin, le site ml-ops.org formalise les principes canoniques.
Cinq cas d’usage industriels où le machine learning crée de la valeur

Les retours mesurés en 2026 montrent jusqu’à 35 pour cent de réduction des arrêts non planifiés grâce à la maintenance prédictive, et 30 à 40 pour cent de fraude en moins sur les meilleures implémentations bancaires. Voici une lecture par algorithme et par secteur que vous pouvez transposer à votre contexte.
| Cas d’usage | Famille | Algorithme type | Impact mesuré |
|---|---|---|---|
| Maintenance prédictive | Supervisé | Random forest, LSTM | -35 % d’arrêts |
| Détection de fraude | Supervisé, semi-supervisé | XGBoost, autoencodeur | -30 à -40 % de fraudes |
| Recommandation produit | Supervisé | Factorisation matricielle | +10 à +20 % de panier |
| Segmentation client | Non supervisé | K-means, DBSCAN | Ciblage affiné |
| Vision industrielle | Supervisé, deep learning | CNN, Vision Transformer | Qualité en temps réel |
Ces cas d’usage s’appuient souvent sur une infrastructure cloud robuste, sujet que nous détaillons dans notre article sur les avantages d’un multi-cloud. Pour l’automatisation des back-offices, lisez aussi l’automatisation du recouvrement client.
Limites, pièges techniques et risques éthiques à connaître

Un modèle n’est jamais meilleur que ses données. Un jeu biaisé produit des décisions biaisées, parfois à grande échelle. Vous devez auditer la représentativité et documenter les limites connues avant toute mise en production.
Le sur-apprentissage reste le piège classique, quand le modèle mémorise le bruit au lieu de généraliser. La dérive de données en production est l’autre ennemi, que seul un monitoring actif permet de détecter à temps. Côté éthique, le MIT Technology Review documente régulièrement les dérives observées sur les systèmes déployés.
Pour finir, l’explicabilité devient un critère de conformité, notamment avec l’IA Act européen entré en application. Les outils comme SHAP et LIME aident à interpréter les décisions, mais ne remplacent pas une gouvernance claire de vos modèles et des responsabilités humaines qui les encadrent.



